
機械学習のモデルを訓練する際に、モデルがどれだけ正確に予測しているかを評価するための重要な概念が「損失関数」と「誤差関数」です。
これらの関数は、モデルの性能を測定し、最適化するために使用されますが、それぞれの役割や違いについて理解しておくことが大切です。
ここでは、損失関数と誤差関数の基本的な概念、違い、そして比較について解説します。
損失関数とは?
損失関数(Loss Function)は、モデルの予測と実際の値との「違い」を定量的に表現する関数です。
機械学習モデルの訓練中に、モデルはデータを基に予測を行いますが、その予測が実際の結果とどれだけ異なっているかを測定するために損失関数が使用されます。値が小さいほど、モデルの予測が実際の値に近いことを示します。
例
- 平均二乗誤差(Mean Squared Error, MSE)
回帰問題でよく使われる損失関数です。予測値と実際の値の差を二乗し、その平均を取ることで、予測のばらつきを計測します。
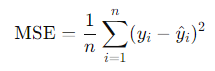
- クロスエントロピー損失(Cross-Entropy Loss)
分類問題でよく使われる損失関数です。予測された確率分布と実際のラベルとの間の差異を測定します。
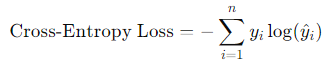
誤差関数とは?
誤差関数(Error Function)は、モデルの予測と実際の値との「違い」を測定するための関数で、損失関数と似た役割を持ちます。
しかし、誤差関数は損失関数とは異なり、誤差をそのまま測定することが多いです。
誤差関数は、損失関数と比較して、直感的に理解しやすい場合があります。
例
- 平均絶対誤差(Mean Absolute Error, MAE)
予測値と実際の値との絶対的な差の平均を取ります。
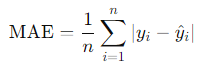
- 平均絶対パーセント誤差(Mean Absolute Percentage Error, MAPE)
絶対誤差を実際の値で割り、パーセント表示にしたものです。
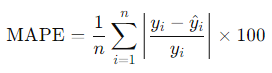
損失関数と誤差関数の違い
損失関数と誤差関数は似た概念ですが、以下の点で異なります:
- 計算方法
損失関数は通常、予測と実際の値との差を二乗するなどして、より強調された誤差を扱います。
一方、誤差関数は差の絶対値など、より直感的な方法で誤差を測定します。
- 用途
損失関数はモデルの最適化に使用される一方で、誤差関数はモデルの性能を評価するための指標として使われることが多いです。
まとめ
損失関数と誤差関数は、どちらも機械学習モデルの性能を評価するために重要な役割を果たします。
損失関数はモデルの訓練プロセスで使用され、予測と実際の値の違いを定量化します。
誤差関数はより直感的な方法でモデルの性能を評価します。
これらの理解を深めることで、機械学習のモデルをより効果的に訓練し、性能を向上させることができます。

