
ChatGPTやClaudeの様なテキスト系の生成AIは、基本的にはロボット的な側面と人間的な側面を取り入れられて作られています。
例えば「報酬にりんごをあげるね」とこちらが伝えると「ありがとうございます、うれしいです。しかし私はAIなので実際に食べることはできませんけどね(笑)」などと返答してきます。
ロボットからのジョークとも取れますが、非常にユーモラスで人間味のある回答です。
ここで今回の本題です。
生成AIはこちらの要求が過多になったり、難しいと判断した場合「ちょっと待ってください」や「現在調査中です」などと、こちらの大器を促す文言を返答することがあります。
これらは本当に我々ユーザー側が何かを待つべきなのでしょうか。
結論としては「待っても何も起こりません」となります。ですので無視して大丈夫です。
無視していいなら何であんなことを言ってくるんだと思われるかもしれません、今回はこういった内容が生成される理由について裏側をお話しします。
AIは何故ユーザーの待機を示唆してくるのか?
では実際にChatGPTに対して挙動を聞いてみましょう。
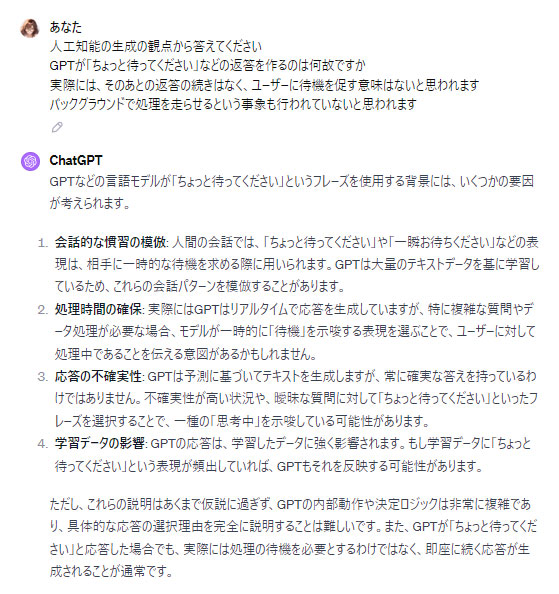
USER
人工知能の生成の観点から答えてください
GPTが「ちょっと待ってください」などの返答を作るのは何故ですか
実際には、そのあとの返答の続きはなく、ユーザーに待機を促す意味はないと思われます
バックグラウンドで処理を走らせるという事象も行われていないと思われます
質問に際し予想を入れて、解答の方向性を決定づけるように促しています。
ChatGPT 4.0
GPTなどの言語モデルが「ちょっと待ってください」というフレーズを使用する背景には、いくつかの要因が考えられます。
- 会話的な慣習の模倣: 人間の会話では、「ちょっと待ってください」や「一瞬お待ちください」などの表現は、相手に一時的な待機を求める際に用いられます。GPTは大量のテキストデータを基に学習しているため、これらの会話パターンを模倣することがあります。
- 処理時間の確保: 実際にはGPTはリアルタイムで応答を生成していますが、特に複雑な質問やデータ処理が必要な場合、モデルが一時的に「待機」を示唆する表現を選ぶことで、ユーザーに対して処理中であることを伝える意図があるかもしれません。
- 応答の不確実性: GPTは予測に基づいてテキストを生成しますが、常に確実な答えを持っているわけではありません。不確実性が高い状況や、曖昧な質問に対して「ちょっと待ってください」といったフレーズを選択することで、一種の「思考中」を示唆している可能性があります。
- 学習データの影響: GPTの応答は、学習したデータに強く影響されます。もし学習データに「ちょっと待ってください」という表現が頻出していれば、GPTもそれを反映する可能性があります。
ただし、これらの説明はあくまで仮説に過ぎず、GPTの内部動作や決定ロジックは非常に複雑であり、具体的な応答の選択理由を完全に説明することは難しいです。また、GPTが「ちょっと待ってください」と応答した場合でも、実際には処理の待機を必要とするわけではなく、即座に続く応答が生成されることが通常です。
つまり、そもそも我々ユーザーに対して待機を期待する応答をする確率は少ないのですが、それでも会話学習により「ちょっと待ってください」と言ってしまう可能性があるわけです。
興味深いですね。
しかし、実際にこちらが待つことで何か処理を行っているのでしょうか?
USER
GPTは応答とは別にバックグラウンドで処理を行いますか?
例えば「ちょっと待ってください」といった発言の際に、応答を一回往復することで精度を向上させるなど明確な狙いがありますか?
ChatGPT 4.0
GPTのような言語モデルは、応答を生成する際にバックグラウンドで別途の処理を行うわけではありません。GPTは入力されたテキストに基づいてリアルタイムで応答を生成し、その過程で追加の待機や処理の往復は発生しません。
「ちょっと待ってください」といったフレーズが生成される場合でも、これはモデルが学習したデータに基づいて最も適切と判断した応答の一部として選ばれるに過ぎず、応答の精度を向上させるための意図的な戦略ではありません。実際には、このような表現が出力された場合でも、モデルは次の応答を即座に生成し、ユーザーに待機を要求する実際の処理は行われません。
GPTの応答は、入力されたテキスト、モデルの学習データ、およびその時点でのモデルの状態に基づいて決定されます。したがって、GPTが「ちょっと待ってください」と応答する場合、それは単にモデルがその時点で最も適切だと判断した言葉を選んだ結果であると考えられます。
つまり、こちらが待つことで進む仕事は存在していないわけです。
さらに追加質問をしてみましょう。
USER
では同様に、「現在調査中です」「タスクを処理しています、時間をください」などのユーザーに待機を促す命令は基本的には模倣から生まれた結果であり特に意味のない返答という理解で合っていますか
生成は確率的な側面があるので、たまに意味の無い内容が入ってくるイメージですね
ChatGPT 4.0
はい、その理解で正しいです。GPTなどの言語モデルが「現在調査中です」や「タスクを処理しています、時間をください」といった応答をする場合、これらは主に模倣から生じた結果であり、実際にモデルが何らかの調査やタスク処理を行っているわけではありません。
言語モデルの応答は、トレーニングデータに含まれるテキストのパターンを基にして生成されます。そのため、モデルは学習過程で見た表現やフレーズを使って応答を構築します。しかし、これはあくまで過去のデータに基づく模倣であり、実際の処理や調査を反映したものではありません。
また、GPTの応答生成は確率的な要素が強く、そのため時には文脈にそぐわない、あるいは意味のない内容が含まれることがあります。これは、モデルが利用可能な情報と統計的な予測に基づいて最も適切と判断した応答を生成するためです。しかし、このプロセスは完璧ではなく、常に完全に理にかなった結果をもたらすわけではありません。
何度か明言されている、学習内容の模倣であることが強調されています。
生成AIの応答は、その応答の作成プロセスからの判断で、これには極めてランダムな要素が含まれるように作られています。
実際に「ちょっと待ってください」といったAIの反応では会話自体は成立しています。しかし、AIが裏でタスクを進めていたり、より精度を上げる方法を模索しているわけではなく、あくまで選択された会話が「待機を促す」であっただけなのです。
ですから、AIが佐を中断してきたときは、単純にタスクを中断されてしまったという事実だけが残るというわけです。
生成失敗とまでは言いませんが、一回分の応答が無駄になっていると考えてよいでしょう。
しかし一つ疑問が浮かびます。
それは、AIが人間に近しくなった時、動作をごまかすことが多くなるのではないかという仮説です。
USER
今後生成モデルが極めて人間的な振る舞いをするようになった場合「意味の無い応答」や「はぐらかす」動作が生成されやすくなると予測します
この予測の上で対策を入れてくるという技術進化になると思いますか?
ChatGPT 4.0
おっしゃる通り、将来的に生成モデルがより人間的な振る舞いを模倣するように進化すると、意味のない応答や話題をはぐらかすような動作が生成される可能性が高まるかもしれません。この予測に基づいて、技術進化の方向性を考えると、次のような対策や進化が期待されます。
- コンテキスト理解の向上: モデルがより精密にコンテキストを理解し、適切な応答を生成できるようになるための研究が進むでしょう。これには、より高度な自然言語理解(NLU)の技術が必要です。
- 応答の関連性と一貫性の向上: モデルが与えられた質問や話題に対して、より関連性が高く一貫性のある応答を生成するためのアルゴリズムの改善が進められます。
- ユーザーの意図の理解: ユーザーの意図や期待をより正確に捉えることが、モデルの応答品質を向上させる鍵となります。これには、対話の文脈を捉える洗練されたメカニズムが必要です。
- フィードバックループの統合: ユーザーからのフィードバックを学習に統合することで、モデルはより実用的で有用な応答を生成するようになるでしょう。
- 倫理的および社会的ガイドラインの遵守: 生成モデルがより洗練されるにつれて、倫理的および社会的な基準を遵守することが重要になります。これには、偏見のない応答生成やプライバシー保護などが含まれます。
総じて、技術の進化は単にモデルの能力を高めるだけでなく、その応答がより有用で、倫理的で、人間のコミュニケーションに適したものであることを保証する方向に進むことが期待されます。
直近の課題ではAIはホリデーシーズンになるとサボる動作が増えることが報告されています。
人間臭くなったAIに我々がどう対応していくべきか、またそれを未然に開発側でどうやって防ぐかは今後の課題かもしれません。

