
ReLU関数とは、深層学習でよく使われる計算方法の一種です。ニューラルネットワークの計算を効率的に行うことができ、学習を早く進めることができます。
シンプルな仕組みでありながら、複雑なデータの学習にも有効です。
ReLU関数がAI開発、特に深層学習にどのように役立つのか?
ReLUの仕組みや特徴について解説いたします。
ReLU関数の概要
ReLU関数(Rectified Linear Unit)は、深層学習(ディープラーニング)における最も広く使われる活性化関数の一つです。
活性化関数は、ニューラルネットワークの各層で計算結果を変換し、モデルの学習能力を向上させるために使用されます。
ReLUは、そのシンプルさと効率性から、多くの機械学習モデルで選ばれています。
ReLUの定義
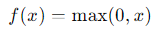
これは、入力 xxx が0より大きければそのままの値を出力し、0以下であれば0を出力するという関数です。
具体的には、ReLU関数は以下のような形をしています。

ReLUのメリット
- 計算効率の良さ
ReLUは非常に単純な計算を行うため、他の活性化関数と比較して計算速度が速いです。
- 勾配消失問題の軽減
勾配消失問題(勾配が消えてしまう現象)が少ないため、深いネットワークの学習がしやすくなります。
- スパースな活性化
多くの入力が0にマッピングされるため、モデルがスパースな表現を学習しやすくなります。
ReLUのデメリット
- ダイイングReLU問題
入力が負の値になると、出力が常に0になってしまうため、ネットワークの一部のニューロンが学習しなくなることがあります。
- 非対称性
正の入力に対しては線形である一方、負の入力に対しては非線形であるため、非対称な性質を持ちます。
他の活性化関数との比較
Sigmoid関数
Sigmoid関数は以下のように定義されます。
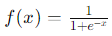
- メリット: 出力が0から1の間に収束するため、確率的な解釈が可能です。
- デメリット: 勾配消失問題が発生しやすく、深いネットワークの学習が難しくなります。
Tanh関数
Tanh(双曲線正接)関数は以下のように定義されます。
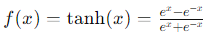
- メリット: 出力が-1から1の間に収束するため、データの中心化が行われ、学習が安定しやすくなります。
- デメリット: 勾配消失問題が発生する可能性があり、計算がSigmoidよりも複雑です。
ReLUと他の活性化関数の比較
- 計算のシンプルさ: ReLUはSigmoidやTanhと比べて計算が簡単です。
- 勾配消失問題: ReLUはSigmoidやTanhに比べて勾配消失問題が少ないです。
- 学習のスピード: ReLUの方が一般的に学習が速いです。
まとめ
ReLU(Rectified Linear Unit)は、シンプルで計算効率が良く、勾配消失問題を軽減するため、深層学習において非常に人気のある活性化関数です。
SigmoidやTanhと比較すると、計算が簡単であり、学習が早いという利点がありますが、ダイイングReLU問題などのデメリットもあります。
他の活性化関数と比較し、タスクやモデルに応じて最適な活性化関数を選ぶことが重要です。

