
ChatGPT4 には、visionという機能があります。2023年初頭にリリースされ、公式サイトでは「ChatGPTは見たり、聞いたり、話したりできるようになりました」と紹介されました。「vision」は画像、動画を理解し、解析してくれるのです。
無料版のChatGPT3.5 にはなかった大きな機能の追加の一つとも言えます。
今回はその機能についてご紹介します。
ChatGPT4 visionとは?画像解析をやってみた
まずは単刀直入に、わかりやすいChatGPT4‐Vの画期的な利用場面をご紹介します。
写真を直接アップロードし、写真について質問するとテキストで回答を得ることができます。
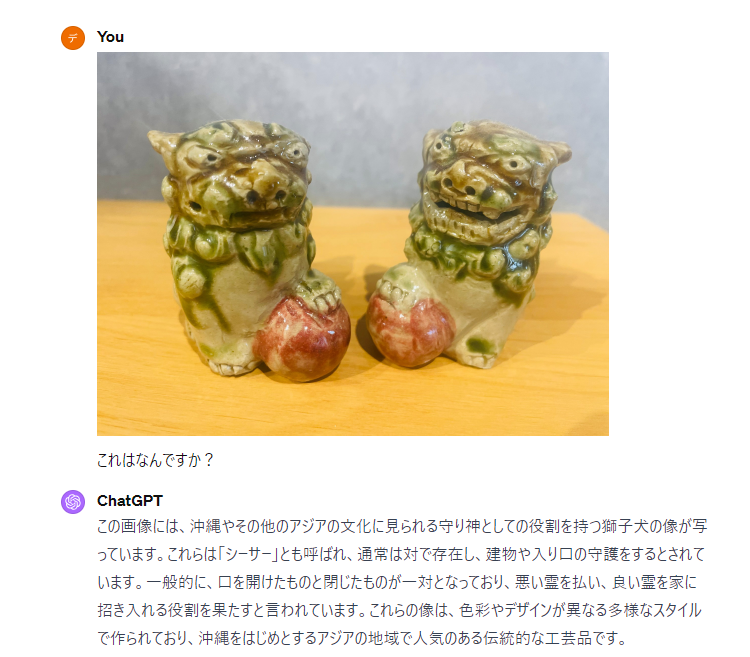
このように、被写体が何か、かつその被写体に関する情報も教えてくれます。こちらは間違いなく、沖縄のシーサーです。
次に、撮影者は「犬の写真」としか説明しずらい写真をChatGPT にプロンプトを入れず投げてみました。


するとChatGPT は、情景の描写及びその犬の表情、犬の心持まで察し回答してくれました。犬種について言及していないため、あえて質問してみましたが「確信をもって犬種を断言できない」という信頼のおける友人のような回答となりました。
次に、情報がばらばらとした写真を入れてみました。


このように画像の持つ情報を整理して言語化し伝達してくれます。
他にも、情報らしい情報を持たない画像や抽象画等の印象を質問すると、印象をテキストで回答してくれる等、まるで生きているかのような存在感です。
ChatGPT4" vision" とは
上記のように楽しい仲間にもなりうる機能ですが、より実践的な観点でChatGPT4" VISION" について掘り下げます。
ChatGPT4" vision" ができる事
- 画像の内容を説明する。
- 画像に基づいて質問に答える。
- 画像からインスピレーションを受けてテキストを生成する(例えば、画像を見て物語を作る)。
生活に生かすなら、下記のような事例が想定されます。
実用編
- 教育: 生徒が描いた図や写真に基づいて、科学的な概念や歴史的な出来事を説明する。
- アートとデザイン: 芸術家が概念やアイデアをテキストで説明し、それに基づいて新しいアートワークやデザインを生成する。
- 医療: 医師がX線やMRIの画像をアップロードし、異常の可能性を示唆する特定の領域について説明を求める。
- エンターテイメント: 映画やビデオゲームのシナリオをテキストで説明し、それに基づいてシーンやキャラクターのビジュアルを生成する。
ChatGPT4" VISION" はなぜ画像が理解できるのか
そもそもなぜ、画像解析ができるのか、それを支える3つの重要な要素があります。
- マルチモーダル学習
- ディープラーニングとトランスフォーマーアーキテクチャ
- 大規模な資金源
これをより詳しく説明します。

マルチモーダル学習
AIの世界では、「モーダル」とは情報を得るための「方法」や「チャネル」を指します。例えば、テキスト(文字)、画像、音声などがそれぞれ異なるモーダルです。テキストモーダルは文字情報を、画像モーダルは視覚情報を、音声モーダルは聞く情報を扱います。
・テキストモーダル: 文字で書かれた情報。例えば、本やメール、ウェブページなど。
・画像モーダル: 写真や図など、目で見る情報。
・音声モーダル: 音や音楽、話し言葉など、耳で聞く情報。
「マルチモーダル」は、これら複数のモーダルを組み合わせて情報を処理することを意味します。たとえば、テキストと画像を一緒に使うことで、より豊かな情報を得たり、より正確に何かを理解したりすることができます。
ディープラーニングとトランスフォーマーアーキテクチャ
ニューラルネットワーク、特にトランスフォーマーと呼ばれるアーキテクチャを使用しており、複雑なデータパターンを捉え、学習する基盤となっています。
- ディープラーニング:
機械学習の一種で、特に「深層学習」とも呼ばれます。ディープラーニングは、人間の脳のニューロン(神経細胞)が情報を処理する方法に触発されています。
これを模倣するため、ディープラーニングでは「ニューラルネットワーク」という数学的なモデルを使用します。このモデルは、多数の層から成り、データを複雑な方法で処理します。
それにより、画像認識、言語理解、予測など、多岐にわたるタスクを実行できます。 - トランスフォーマーアーキテクチャ:
これはニューラルネットワークの一種で、特に言語処理の分野で革新的な成果を上げています。
トランスフォーマーは「自己注意機構」と呼ばれる技術を使い、入力されたデータの中で最も重要な部分に注目して処理を行います。
たとえば、文章を解析する際、特定の単語やフレーズの意味をより深く理解するために、文脈全体の中でそれらに注目します。このアーキテクチャは、ChatGPT-4を含む多くの先進的なAIシステムの基盤となっています。
ChatGPTに上記をイメージさせる絵を描かせると下記のような絵と説明が返ってきました。大変わかりやすいと感じます。
- ディープラーニングの部分: ニューラルネットワークが多層構造で示されており、複雑なデータパターンを処理する様子を表しています。
- トランスフォーマーアーキテクチャの部分: 自己注意機構が描かれており、入力データの異なる部分に焦点を当てる方法が強調されています。これは特に言語処理において重要です。
膨大な資金源
急に大変現実的な要素となりますが、これは欠かせません。
ChatGPT-4のような高度なAIモデルを訓練するためには、膨大な量のデータを処理する必要があります。
このデータには、テキスト、画像、音声など、多様な形式が含まれます。これらのデータを効率的に処理し、学習させるためには、高い計算能力が必要です。
ディープラーニングモデル、特にトランスフォーマーモデルは、その構造が複雑で、多くの計算を必要とします。これらの計算を実行するためには、高性能のプロセッサや大量のメモリ、高速なストレージなどが必要です。
これらの計算資金源を組み合わせる事で、OpenAIはChatGPT-4のような大規模で複雑なAIモデルを効果的に訓練し、運用することができます。
このように、最後の要素は超現実的ですが、それなくしてテクノロジーの進化なし。今後の展開がますます楽しみです。

